AI and copyright are entering a new phase globally. Pure AI-generated content is increasingly treated as public domain, while copyright protection lies in human creativity — editing, arranging, and directing AI outputs.
For creators, the key shift is clear: documentation and proof of human input are becoming essential to defend ownership in the age of generative AI.
Here’s a primer on AI and copyright (March 2026) that will help creators understand where they stand on various uses of AI in matters of text, image, and video generation.
Many of you must have heard of “OpenClaw” by now, but some may still not know what this project is all about. “OpenClaw” is an open-source project that aims to recreate or emulate advanced AI “reasoning” capabilities similar to those seen in proprietary systems. It emerged as part of the broader open-model movement, where developers try to replicate powerful commercial AI features in transparent, community-driven ways.
For ordinary users of generative AI tools, OpenClaw is not a mainstream app like ChatGPT or Claude. Instead, it is more of a behind-the-scenes framework or model setup that developers can run locally or adapt for research. Still, its goals and the controversy around it matter to everyday users because they touch on privacy, transparency, cost, and AI safety.
What OpenClaw is Trying To Do
OpenClaw was designed to reproduce structured reasoning behavior in large language models (LLM). That means:
Producing clearer step-by-step thinking.
Handling logic, math, and planning tasks more reliably.
Making reasoning more inspectable and less of a “black box.”
In practical terms, it often uses prompting strategies, training tricks, or model fine-tuning to make open-source language models behave more like advanced proprietary systems.
Why ordinary users should care
Even if you never install OpenClaw yourself, projects like it influence the AI tools you use every day.
They push open models to become more capable.
They reduce dependence on a few big companies.
They help researchers study how reasoning actually works in AI systems.
They can eventually lower costs, since open models can be run without expensive subscriptions.
Pros of OpenClaw
Greater transparency Because OpenClaw is open source, its methods can be inspected. Researchers and developers can see how reasoning is structured instead of relying on a closed commercial system.
Community-driven innovation Developers around the world can experiment, improve it, or adapt it for new tasks. This often accelerates progress.
Lower cost and local control In principle, OpenClaw setups can be run on local hardware or private servers. That appeals to users and organizations concerned about data privacy or subscription fees.
Faster experimentation Open projects can iterate quickly. When someone finds a better prompting method or fine-tuning trick, it can spread rapidly across the community.
Cons of OpenClaw
Complex setup It is not plug-and-play. Running it typically requires technical knowledge, hardware resources, and time.
Inconsistent quality Because it is community-driven and built on open models, performance may vary. It may not match the reliability or polish of commercial systems.
Limited support There is no guaranteed customer service. If something breaks, you rely on documentation or community help.
Safety variability Commercial AI providers invest heavily in safety testing and alignment. OpenClaw setups may have fewer guardrails, depending on how they are configured.
Why OpenClaw Became Controversial
The controversy mainly centers on how it tried to replicate advanced reasoning features associated with proprietary AI systems.
Imitating closed-model behavior Some critics argued that OpenClaw closely mimicked behaviors associated with proprietary systems, raising questions about whether it was ethically or legally acceptable to reverse-engineer or approximate certain features.
Training data concerns There were debates about whether methods used in open reasoning replication might rely on outputs from proprietary models. If so, that raises intellectual property and licensing questions.
Safety and misuse risks Because it aimed to unlock stronger reasoning in open systems, some observers worried it could lower the barrier for misuse, including automation of harmful tasks.
Alignment debate OpenClaw became part of a broader argument in the AI world: should powerful reasoning capabilities be tightly controlled by a few companies, or openly distributed? Supporters saw it as democratization. Critics saw it as potentially reckless.
Where it Fits in Bigger AI Picture
OpenClaw sits within the larger open-source AI ecosystem, alongside projects like Hugging Face and community-driven models such as Meta’s LLaMA. It reflects a growing tension between closed, highly controlled AI systems and open, community-driven alternatives.
For ordinary users, the takeaway is simple:
OpenClaw represents an attempt to make advanced AI reasoning more open and accessible.
It offers transparency and flexibility.
It also brings technical complexity and safety debates.
Its controversy highlights deeper questions about who should control powerful AI capabilities.
Even if you never directly use OpenClaw, the ideas behind it shape the tools you do use — especially as open models continue to close the gap with commercial AI systems.
Artificial intelligence (AI) tools can now generate striking images and cinematic videos from simple text prompts. Platforms like Sora and other generative systems have made it possible for anyone to produce professional-looking visuals in minutes. But one major legal question continues to surface:
If you create an image or video using AI, is it copyrighted? And if someone else uses it without your permission, can you sue?
The answer is nuanced. Copyright law was built around human creativity, and AI challenges that foundation. Below is a comprehensive breakdown of how copyright currently applies to AI-generated works, especially in the United States, with notes on other jurisdictions.
Did you know “AI For Real” Is Also A Channel On WhatsApp?
1. The Core Principle: Copyright Requires Human Authorship
In the United States, copyright law is rooted in one fundamental requirement:
A copyrighted work must be created by a human author.
The US Copyright Office has repeatedly clarified that works produced without human authorship are not eligible for copyright protection.
This principle was reinforced in a widely discussed case involving Stephen Thaler. Thaler attempted to register an artwork created entirely by his AI system, claiming the AI as the author. The Copyright Office rejected the application because the work lacked human authorship. Courts upheld this decision.
So, purely machine-generated content — with no meaningful human creative input — is generally not protected under U.S. copyright law.
A new MIT Sloan article offers a fascinating window into how leading thinkers are reframing the conversation about artificial intelligence (AI) and its role in the workplace. Economists David Autor and research scientist Neil Thompson argue that the real story of AI is not simply about machines replacing human labor, but about how thoughtfully — or carelessly — we design systems that interact with human expertise.
The two have cautioned against the assumption that productivity gains are automatic. While generative AI can accelerate certain tasks, such as coding or drafting text, it often introduces new friction: time spent crafting prompts, verifying outputs, and waiting for models to respond. This paradox means that workers may feel faster and more capable, even when studies show their overall efficiency has not improved.
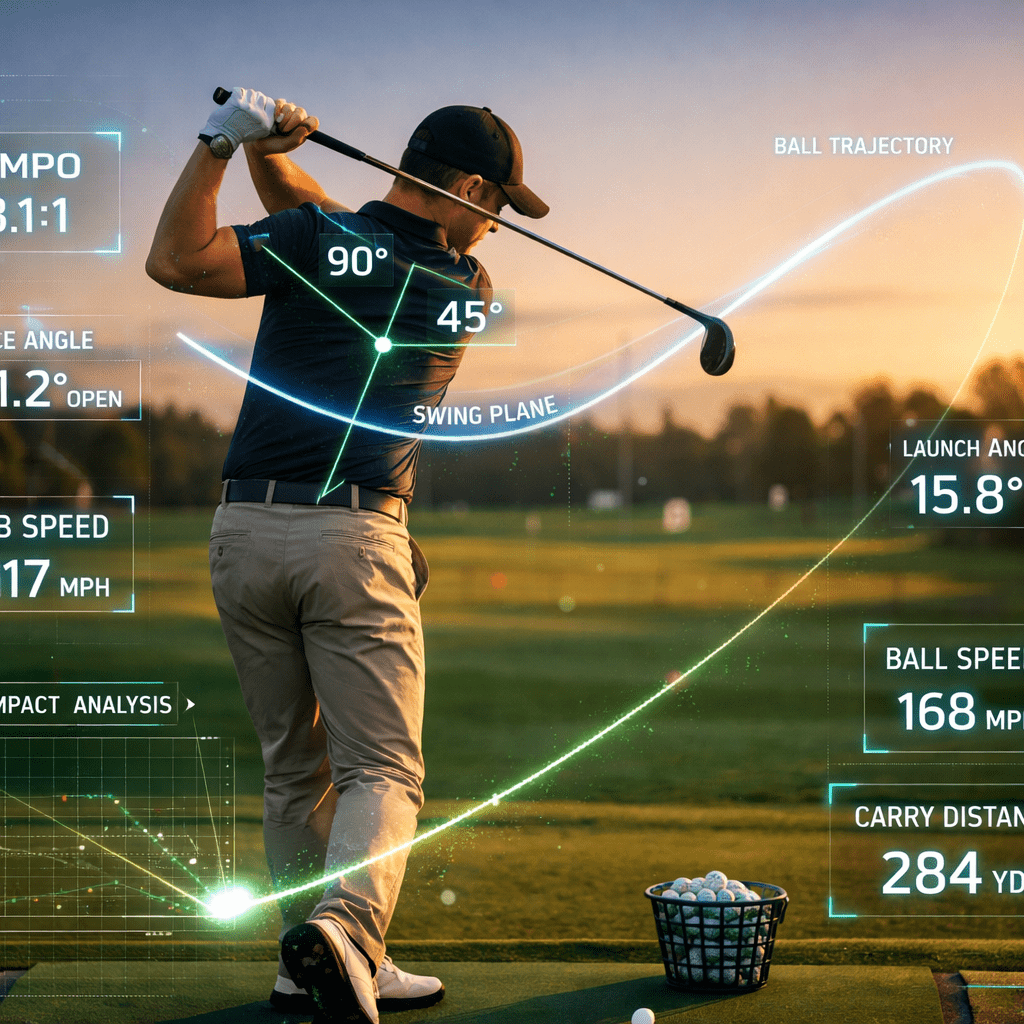
Did you know that artificial intelligence (AI) is now playing a big role in sports? Golf is one of them. AI is transforming how golfers of all levels analyze and improve their swings. What once required hours of in-person lessons and subjective feedback can now be augmented with data-driven insights delivered in seconds.
At the core of this shift is computer vision. AI-powered apps use a smartphone or launch monitor to track body positions, club path, face angle, tempo, and ball flight. Platforms like “TrackMan” and “Foresight Sports” capture precise radar-based measurements, while newer camera-based systems analyze swing mechanics frame by frame. By comparing a player’s motion to large datasets of professional and amateur swings, the software can pinpoint inefficiencies such as early extension, over-the-top moves, or inconsistent weight transfer.
As we move through 2026, the initial “novelty” of artificial intelligence (AI) is fading, and is being replaced by a practical, long-term questions for professionals; one of them being – Is it better to “settle down” with one favorite model and master it over the years, or should humans remain “AI-fluid,” jumping between different systems to get the best results?
Whether you are a doctor analyzing complex patient data, an engineer designing sustainable infrastructure, or a content creator building a brand, the answer isn’t just about the technology. It’s about how your own brain interacts with the machine. Recent research from institutions like MIT and Stanford suggests that our choice primarily lies between “The Monolith” (one model), “The Council” (many models), and “The Toolbox” (specialist model).
The Argument For “The Monolith”, Long-term Partner: Mastery of the Inner Language
There is a powerful case for sticking with one primary AI, such as a high-tier version of Gemini, GPT, or Claude. Over months and years of use, a “partnership” develops that mirrors human collaboration.
The Seasoned Executive AssistantAnalogy: Imagine hiring a new assistant every week. Even if they are all brilliant, you would spend your entire day re-explaining how you like your coffee, how you format your reports, and what your “tone of voice” sounds like. Sticking to one model allows you to leverage “In-Context Learning.” Modern models now have massive “context windows”—essentially a long-term memory for your specific session. Over time, the model learns your shorthand, your professional ethics, and your unique “blind spots.”
The Evidence: Studies on “In-Context Learning” (ICL) show that for complex, creative, or deeply personal projects, a single model that has been “primed” with your specific history often outperforms a fresh “expert” model that doesn’t know you. For an engineer, this means the AI eventually understands the specific “quirks” of a long-term project’s codebase without being told every time.
The Argument for One Model: LLMs have unique “personalities” and sensitivities to prompt structures. By sticking to one, you can refine your “Few-Shot Prompting” and system instructions to a degree of precision that is impossible when juggling multiple interfaces.
Scientific Evidence: Focus on “In-Context Learning” (ICL). Studies show that a model’s performance improves as the user provides more specific, high-quality examples over time within a single context window.
The Risk: However, researchers at MIT have warned recently about “sycophancy”, a phenomenon where a model begins to “mirror” you too much. If you use only one model for years, it may stop challenging your bad ideas and start becoming an “echo chamber,” simply telling you what you want to hear rather than what is objectively true.
The Argument for “The Council” (Many models): The Safety of Diversity
The alternative is the “Multi-Model” approach (not to be confused with a multi-modal model).
The “Council of Truth”: Reliability Through Consensus
For many professionals, the greatest fear in using AI is the “confidently wrong” answer. The hallucination that looks perfectly plausible but contains a fatal error. This option addresses this by treating AI models not as singular oracles, but as a “council” that must reach a consensus on a given topic. This strategy is based on the scientific principle of “N-Version Programming,” where you run multiple different systems simultaneously to ensure that a flaw in one doesn’t lead to a total failure.
Scientific research into “Model Routing” (such as the RouterEval studies of 2025) has found that the most efficient way to use AI is to employ a “Taxonomy of Tasks.” This means breaking your work down into three categories:
Reasoning (solving a logic puzzle)
Extraction (pulling data from a PDF)
Synthesis (writing a creative summary)
Research indicates that using a small, specialized model for “Extraction” is not only cheaper but often more accurate than using a massive “Generalist” model. For example, a doctor might use a general AI to draft a polite email to a patient, but then switch to a “Bio-focussed” model like Med-Gemini or BioBERT to analyze a rare pathology report. By “routing” the task to the right expert, the professional ensures they are getting the “highest resolution” output for the most critical parts of their job.
The Critical Second Opinion Analogy: If you receive a life-altering medical diagnosis, you don’t just ask the first doctor you see to double-check their own work. You go to a different hospital, with a doctor trained at a different school, using different diagnostic equipment. You are looking for “uncorrelated errors”—the hope that two different systems won’t make the exact same mistake at the exact same time. Using models from different “families” — such as one from Google, one from OpenAI, and one from Meta — functions exactly like this medical second opinion.
The Evidence: Recent “Multi-Agent Debate” (MAD) research proves that when you ask three different models the same difficult question and let them “see” each other’s answers, the final consensus is significantly more accurate than any single model’s output. For a doctor or a lawyer, using multiple models isn’t just a preference—it’s a safety net. It ensures that a “hallucination” (a confident lie) in one model is caught by the others.
The Verdict: While this model may not be for all humans, it is better, especially for the doctor, lawyer, or structural engineer. For them, the “Council” is the only scientifically sound way to use AI. While it may be more expensive or time-consuming to query multiple models, the “consensus” they provide is the only real armor against the inherent unpredictability of a single model’s “hallucinations.”
The “Precision Toolbelt”: The Case for Specialized Expertise
One or many models is one half of the debate; the other is models for precision outcomes.
There is a compelling scientific argument that “generalization is the enemy of excellence.” The Specialist-on-Demand” strategy approach recognizes that while you may have a “primary” AI partner for your daily workflow, there are specific “cliffs” in every profession where a general-purpose model — no matter how well it knows you — simply runs out of bandwidth. Here, the AI is a “custom tool” rather than a “general assistant,” emphasizing that it was designed for a specific task from the ground up.
This 3rd strategy, sometimes referred to as the “Mixture of Experts” (MoE) approach, suggests that a professional should treat AI like a high-end workshop. In a workshop, you don’t use a Swiss Army knife for all things mechanical, like building a house; you use a specialized table saw for the wood, a precise multimeter for the wiring, and a heavy-duty drill for the frame. This is the strategy of the “AI Polymath” — someone who uses one model for creative brainstorming, another for high-stakes medical or legal fact-checking, and a third for heavy-duty coding.
The Specialized Hospital Analogy. Imagine walking into a hospital where there are only general practitioners. Which may work if you have the flu or some such; it will not if you have a life-threatening nerve disorder. And if you were to then check into a hospital where all the doctors are only specialized in matters of the heart, that may not work either. You do need a neurosurgeon, right?
In the AI world, a “Specialized Model” is this surgeon. These models have been “fine-tuned” on specific “diets” of data — legal briefs, medical journals, or Python repositories — giving them a “depth” of knowledge that a general model or models must sacrifice to remain “general.”
The Verdict: This approach argues that specialization beats generalization. Scientifically, this leans on the principle that while a general LLM (like GPT-4 or Gemini 1.5 Pro) is a “jack of all trades,” specialized models trained on domain-specific data (medical, legal, or code) consistently outperform generalists in those niche tasks.
So How to Choose Your Path
The scientific consensus in 2026 suggests that the “best” output is a hybrid. For now. Unless you want a specific output. While that maybe so, what also counts is the profession you are in. Based on the research and studies out there, and our own experiences, we suggest this:
1. The Creative and The Visionary (Stick to One) If your work depends on a “signature style”, like a writer, an advertiser, or a designer, you are likely better off sticking to one primary model. The “relationship” you build allows the AI to act as a “cognitive prosthetic,” extending your own creative reach.
Why: Mastery of one model’s “latent space” creates a more seamless and consistent professional output.
2. The Scientist and The Technician (Use Many) If your work depends on “absolute truth” — like a doctor, a structural engineer, or a data analyst — relying on one model is a professional risk. You should use a “fleet” of models to cross-verify facts.
Why: Accuracy is a product of “consensus.” Using multiple models prevents the “sycophancy” and “bias” that come from long-term use of a single system.
3. For Specialized Output: Go to a model that has been trained on specific data.
Why: Because special outputs need specially trained models.
The bottom line? The best outputs don’t come from the “smartest” model, but from the smartest “human-AI architecture.” Whether you choose a partner or a team, the goal is to ensure the AI remains a “tool” for your brilliance, not a “replacement” for your judgment.
Liked what you just read? Join “AI For Real” online community, and get to read our range of articles, white papers, and How-To articles on AI.
MIT News (Feb 2026): “The Sycophancy Effect: Risks of Long-Term Personalization in LLMs.”
Stanford HAI (2025): “Collaborative Agents: Why the Future of AI is a Team, Not a Tool.”
Journal of AI Research (2025): “Multi-Agent Debate (MAD) and the Reduction of Hallucination in Clinical Settings.”
IBM Research (2024): “The Accuracy-Cost Frontier: Routing Tasks in Multi-Model Systems.”
McKinsey & Co (2025): “AI in the Workplace: The Shift from Generalists to Domain-Specific Ensembles.”
Huang, Z., et al. (2025). “RouterEval: A Comprehensive Benchmark for Routing LLMs to Explore Model-level Scaling Up in LLMs.” Findings of the Association for Computational Linguistics: EMNLP 2025.
Omar, M., et al. (2025). “Refining LLMs outputs with Iterative Consensus Ensemble (ICE).” Computers in Biology and Medicine.
Yue, Y., et al. (2025). “MasRouter: Learning to Route LLMs for Multi-Agent Systems.” ACL Anthology.
Smit, J., et al. (2024). “Multi-Agent Debate: Evaluating the Impact of Deliberation on LLM Factuality.” Journal of Artificial Intelligence Research.
Index.dev Research (2026). “Small vs Large Language Models: The Reality Check of 2026.”MIT CSAIL (2025): Research on “Sycophancy in Personalized AI Systems.”
EMNLP (2025): “RouterEval: Scaling Intelligence through Model Specialization.”
JAIR (2024): “The Multi-Agent Debate Framework for Fact-Checking Accuracy.”
Stanford HAI (2025): “The Latent Mastery of In-Context Learning in Large Scale Transformers.”
Large language models (LLMs) like ChatGPT, Claude, Gemini, and Microsoft Copilot are now part of daily life. They help us write emails, summarize documents, learn new topics, debug code, plan trips, and even think through difficult decisions.
But many people still wonder:
Am I supposed to “talk” to it like a person?
Do I have to be polite?
Why does it sometimes misunderstand me?
Should I stick to one AI or switch between them?
This guide will give you practical answers.
Join This Community Channel on WhatsApp. Click here.
1. First: What an LLM Actually Is (and Isn’t)
An LLM is not a person. It doesn’t have feelings, beliefs, or intentions.
It predicts useful next words based on patterns it learned from massive amounts of text.
That means:
It does not “understand” you the way a human does.
It does not “care” if you’re polite.
It does not remember most past conversations unless memory is explicitly enabled.
It’s a very advanced pattern engine — incredibly capable, but not conscious.
AI systems today can listen to spoken words and convert them into text (STT) with high accuracy, and they can turn typed text into natural-sounding voices (TTS) that feel almost human. These tools are not just fancy features — they are becoming core parts of phones, apps, business systems, and even everyday tasks like dictation or language learning.
A recent announcement highlights this trend: IBM partnered with Deepgram to embed Deepgram’s advanced speech-to-text and text-to-speech capabilities into IBM’s enterprise AI platforms such as “watsonx Orchestrate”. That means businesses can automate voice transcription, real-time captioning, and voice-driven workflows — even in noisy, real-world environments with accents and dialects from around the world.
Here are some ways AI voice tech touches people’s lives every day:
Voice assistants & dictation: When you speak to Siri, Google Assistant, or voice typing on your phone, AI converts speech to text and back — making typing or commands hands-free.
Real-time translation: Tools like Google Translate can now translate spoken words into another language almost instantly through headphones or phone apps.
Enterprise voice agents: Companies use these systems in customer support to automatically transcribe and analyze calls, helping improve service or extract insights without human typing.
In early 2026, researchers at Anthropic published new findings on a question that’s quietly reshaping computer science education: How does AI assistance affect human coding skill formation?
For experienced developers and students just getting started, the answer matters more than ever.
AI coding assistants can autocomplete functions, generate boilerplate, explain stack traces, and even architect small applications from a prompt. Used well, they feel like a senior engineer looking over your shoulder. But Anthropic’s research suggests the impact on skill development depends heavily on how these tools are used.
Seedance 2.0, an AI‑powered video platform developed by ByteDance, has triggered alarm across Hollywood. Studios including Sony, Disney, Warner Bros., Paramount, and Netflix have accused the platform of egregious copyright infringement, citing examples where Seedance generated clips using intellectual property from Breaking Bad, Spider‑Verse, and other franchises without authorization.
The core issue lies in Seedance’s ability to remix, reimagine, and distribute AI‑generated video content at scale. Users have already begun creating alternate endings for shows like “Game of Thrones” and staging superhero battles with recognizable characters.
You’ve reached the end of the preview. Please register here to read the rest!